
راهاندازی و رفع مشکلات HA و DRS در vmware
آموزش جامع راه اندازی Cluster در VMware | مرجع کامل HA، DRS، FT و EVC
در عصر دیجیتال امروز، “توقف سرویس” (Downtime) واژهای ممنوعه در دیتاسنترهاست. مدیران شبکه همواره با چالش پایداری روبرو هستند. چگونه میتوانیم مطمئن شویم که خرابی یک سرور فیزیکی، منجر به توقف اپلیکیشنهای حیاتی سازمان نمیشود؟ پاسخ در تکنولوژی قدرتمند کلاسترینگ نهفته است. راه اندازی cluster در vmware سنگ بنای یک دیتاسنتر مدرن و تابآور است. با استفاده از قابلیتهایی نظیر High Availability (HA)، Distributed Resource Scheduler (DRS) و Fault Tolerance (FT)، شما لایهای از هوشمندی را به زیرساخت خود اضافه میکنید که میتواند خود را ترمیم و مدیریت کند.
ما در NetHelper با سالها تجربه در پروژههای Enterprise، این راهنمای جامع را تدوین کردهایم. در این مقاله، ما فراتر از تنظیمات اولیه میرویم و به عمق مفاهیم فنی مثل راه اندازی drs برای بهینهسازی منابع، راه اندازی ft در vmware برای سرویسهای بدون قطعی و معماری پیچیده راه اندازی vcenter ha میپردازیم. همچنین مباحث پیشرفتهای مثل EVC Mode و DPM را بررسی خواهیم کرد. اگر به دنبال تبدیل شدن به یک معمار ارشد مجازیسازی هستید، این مقاله نقشه راه شماست.
فهرست مطالب (سرفصلهای تخصصی کلاسترینگ)
- مفاهیم بنیادی: چرا راه اندازی cluster در vmware ضروری است؟
- کالبدشکافی HA: تنظیمات Admission Control و Heartbeat
- راه اندازی drs پیشرفته: Affinity Rules و Predictive DRS
- راه اندازی ft در vmware: تکنولوژی SMP-FT و الزامات شبکه
- نقش حیاتی EVC Mode در پایداری vMotion
- معماری راه اندازی vcenter ha (Active, Passive, Witness)
- مدیریت مصرف انرژی با DPM (Distributed Power Management)
- عیبیابی خطاهای رایج در کلاسترینگ
مفاهیم بنیادی: چرا راه اندازی cluster در vmware ضروری است؟
در معماری سنتی، هر سرور فیزیکی (Host) یک جزیره جداگانه بود. اگر منابع آن سرور تمام میشد یا سختافزارش خراب میشد، تمام ماشینهای مجازی (VM) روی آن تحت تأثیر قرار میگرفتند. راه اندازی cluster در vmware این پارادایم را تغییر میدهد. کلاستر، مجموعهای از هاستهای ESXi است که منابع CPU و RAM خود را تجمیع کرده و به عنوان یک “کامپیوتر واحد و غولپیکر” در اختیار هایپروایزر قرار میدهند.
وقتی شما اقدام به راه اندازی cluster در vmware میکنید، دیگر مهم نیست VM شما روی کدام سرور فیزیکی اجرا میشود. لایه مجازیسازی تصمیم میگیرد که بر اساس بار کاری و سلامت سختافزار، ماشین مجازی کجا قرار بگیرد. این “انتزاع سختافزار” کلید اصلی دستیابی به SLAهای بالا (مثلاً ۹۹.۹۹۹٪) است. بدون کلاستر، مفاهیمی مثل Maintenance Mode (حالت تعمیرات) بدون خاموشی سرویس، عملاً غیرممکن است.
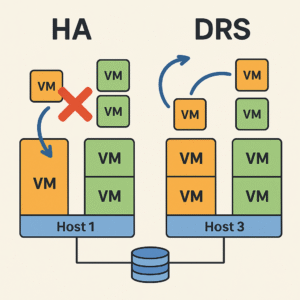
کالبدشکافی HA: تنظیمات Admission Control و Heartbeat
بسیاری از ادمینها تصور میکنند راه اندازی HA فقط زدن یک تیک است. اما در محیطهای Enterprise، پیکربندی دقیق آن حیاتی است. HA (High Availability) از یک ایجنت به نام FDM (Fault Domain Manager) استفاده میکند که روی تمام هاستها نصب میشود. یک هاست به عنوان Master انتخاب شده و وضعیت بقیه (Slaves) را پایش میکند.
1. کنترل پذیرش (Admission Control)
یکی از پیچیدهترین بخشها در راه اندازی cluster در vmware، تنظیمات Admission Control است. این قابلیت تضمین میکند که کلاستر همیشه ظرفیت خالی کافی برای روشن کردن VMها در زمان خرابی داشته باشد. شما میتوانید این ظرفیت را به سه روش رزرو کنید:
- Slot Policy: محاسبه بر اساس بزرگترین VM (محافظهکارانه).
- Cluster Resource Percentage: رزرو درصدی از کل منابع (مثلاً ۲۰٪ CPU و RAM). این روش انعطافپذیرترین حالت در راه اندازی cluster در vmware است.
- Dedicated Failover Host: اختصاص یک سرور فیزیکی بیکار فقط برای زمان خرابی (هزینهبر).
2. Datastore Heartbeating
گاهی اوقات شبکه مدیریت قطع میشود اما سرور سالم است. برای جلوگیری از تشخیص اشتباه (False Positive) و رخداد Split-Brain، در راه اندازی cluster در vmware از Datastore Heartbeat استفاده میشود. هاستها از طریق فایلهای قفلشده روی استوریج مشترک (SAN/vSAN) به Master اعلام زنده بودن میکنند. توصیه میشود حداقل ۲ دیتاستور مختلف برای این کار انتخاب شود.
راه اندازی drs پیشرفته: Affinity Rules و Predictive DRS
هدف از راه اندازی drs، متعادلسازی بار (Load Balancing) است. DRS هر ۵ دقیقه بار سرورها را چک میکند و در صورت عدم تعادل، پیشنهاد مهاجرت (vMotion) میدهد. اما در نسخههای جدید vSphere، قابلیتهای جذابی اضافه شده است:
Predictive DRS (DRS پیشبینانه)
با ترکیب vRealize Operations Manager و راه اندازی drs، سیستم میتواند رفتار VMها را یاد بگیرد. مثلاً اگر دیتابیس شما هر دوشنبه صبح ساعت ۸ اوج مصرف دارد، DRS پیشبینانه از ساعت ۷:۳۰ منابع را خالی میکند و VM را به قویترین هاست منتقل میکند، قبل از اینکه کندی رخ دهد!
قوانین Affinity و Anti-Affinity
در راه اندازی drs، شما معمار ترافیک هستید. با قوانین Affinity میتوانید بگویید “VM وبسرور و VM دیتابیس همیشه روی یک هاست باشند” تا ترافیک شبکه داخلی بماند. برعکس، با Anti-Affinity میتوانید بگویید “دو دامین کنترلر (DC) هرگز روی یک هاست نباشند” تا اگر یک سرور سوخت، کل سرویس AD از دست نرود. تنظیم صحیح این قوانین در راه اندازی cluster در vmware نشاندهنده بلوغ دیتاسنتر شماست.
راه اندازی ft در vmware: تکنولوژی SMP-FT و الزامات شبکه
سرویس HA برای ۹۹٪ موارد کافی است، اما برای آن ۱٪ سرویسهای فوقحساس، حتی ۳ دقیقه زمان ریستارت شدن هم فاجعه است. اینجاست که راه اندازی ft در vmware وارد میشود. FT (Fault Tolerance) یک کپی سایه (Secondary VM) روی هاست دیگر میسازد که با تکنولوژی vLockstep دقیقاً همگام با ماشین اصلی (Primary VM) کار میکند.
در نسخههای قدیمی، FT محدود به ۱ هسته پردازشی بود. اما با معرفی SMP-FT، اکنون میتوانیم برای ماشینهای چند هستهای (تا ۸ vCPU در نسخههای Enterprise Plus) نیز راه اندازی ft در vmware را انجام دهیم. با این حال، FT سربار زیادی دارد و نیازمندیهای آن خاص است:
- تأخیر شبکه: شبکه FT Logging باید زیر ۱ میلیثانیه لتنسی داشته باشد (الزاماً 10GbE).
- سازگاری CPU: پردازندههای هاستها باید دقیقاً از یک خانواده باشند.
- لایسنس: برای استفاده از تمام ظرفیت، به بالاترین سطح لایسنس نیاز دارید.
کارشناسان NetHelper پیش از راه اندازی ft در vmware، تستهای دقیق شبکه و پکتلاست را انجام میدهند تا از عملکرد صحیح این سرویس حساس اطمینان حاصل کنند.
نقش حیاتی EVC Mode در پایداری vMotion
یکی از چالشهای رایج در راه اندازی cluster در vmware، ناهمگن بودن سختافزار است. مثلاً شما سرورهای HP G9 با پردازنده قدیمی دارید و حالا سرورهای HP G10 با پردازنده جدید خریدهاید. به طور پیشفرض، vMotion بین این دو نسل پردازنده انجام نمیشود چون دستورالعملهای CPU (Instruction Sets) متفاوت هستند.
برای حل این مشکل، باید EVC (Enhanced vMotion Compatibility) را فعال کنید. EVC با ایجاد یک “کف مشترک” (Baseline) از ویژگیهای CPU، به تمام هاستها دستور میدهد که فقط از ویژگیهای آن نسل مشترک استفاده کنند. این کار باعث میشود vMotion و DRS در کلاسترهای ناهمگن به درستی کار کنند. فعالسازی EVC یکی از چکلیستهای اصلی ما در راه اندازی cluster در vmware است.
معماری راه اندازی vcenter ha (Active, Passive, Witness)
قلب تپنده مدیریت مجازیسازی، vCenter Server Appliance (VCSA) است. اگر vCenter از دسترس خارج شود، ماشینهای مجازی به کار خود ادامه میدهند، اما شما قابلیتهای مدیریتی، مانیتورینگ، کلون گرفتن و تغییرات DRS را از دست میدهید. برای سازمانهای بزرگ، راه اندازی vcenter ha یک الزام است.
معماری VCHA بر پایه سه نود بنا شده است که از طریق یک شبکه خصوصی (Private Network) با هم در ارتباط هستند:
- Active Node: نودی که IP مدیریتی را دارد و سرویسها را اجرا میکند.
- Passive Node: نودی که دیتابیس PostgreSQL و فایلهای تنظیمات به صورت لحظهای (Synchronous Replication) روی آن کپی میشوند.
- Witness Node: نود شاهدی که در صورت قطعی شبکه بین دو نود اصلی، تعیین میکند کدام نود باید Master شود تا از Split-brain جلوگیری کند.
راه اندازی vcenter ha نیازمند طراحی دقیق شبکه است. باید یک پورتگروپ جداگانه با Latency کمتر از ۱۰ میلیثانیه برای ترافیک Replication اختصاص داد. تیم نتهلپر این معماری را به گونهای پیادهسازی میکند که حتی در صورت سوختن کامل سرورِ vCenter، کنسول مدیریتی در کمتر از ۵ دقیقه به صورت خودکار بازیابی شود.
مدیریت مصرف انرژی با DPM (Distributed Power Management)
در دیتاسنترهای بزرگ، هزینه برق و کولینگ سرسامآور است. تکنولوژی DPM یک مکمل برای راه اندازی drs است. فرض کنید در ساعات شب، بار کاری سرورها به شدت کم میشود و تمام سرورها با ۱۰٪ توان کار میکنند. DPM این وضعیت را تشخیص داده و با استفاده از vMotion، تمام ماشینهای مجازی را روی چند سرور محدود تجمیع میکند.
سپس، DPM دستور خاموشی (Standby Mode) را به سرورهای خالی میفرستد تا برق مصرف نکنند. صبح روز بعد که بار کاری زیاد شد، DPM از طریق تکنولوژی IPMI/iLO دستور Wake-on-LAN را ارسال کرده و سرورها را روشن میکند. راه اندازی cluster در vmware همراه با DPM میتواند تا ۳۰٪ در هزینههای انرژی دیتاسنتر صرفهجویی کند.
عیبیابی خطاهای رایج در کلاسترینگ
حتی با بهترین پیادهسازی، مشکلات رخ میدهند. تجربه ما در پروژههای متعدد راه اندازی cluster در vmware نشان میدهد که خطاهای زیر رایجترین هستند:
- خطای “vSphere HA Agent Unreachable”: این خطا معمولاً نشاندهنده مشکل در شبکه Management یا پورتهای فایروال (TCP/UDP 8182) است. گاهی اوقات Reconfigure HA مشکل را حل میکند.
- خطای “Insufficient Resources to Satisfy Configured Failover Level”: این یعنی تنظیمات Admission Control شما خیلی سختگیرانه است یا منابع کلاستر واقعاً پر شده است. باید یا Slot Size را تغییر دهید یا منابع فیزیکی اضافه کنید.
- عدم تعادل DRS: اگر DRS با اینکه روی Fully Automated است VMها را جابجا نمیکند، احتمالاً vMotion شبکه مشکل دارد یا قوانین Affinity سختگیرانهای تعریف کردهاید که دست DRS را بسته است.
آیا آمادهاید دیتاسنتر خود را ضدگلوله کنید؟
پایداری اتفاقی نیست؛ نتیجه مهندسی دقیق است. راه اندازی cluster در vmware، راه اندازی drs هوشمند، راه اندازی ft در vmware برای سرویسهای مالی و راه اندازی vcenter ha برای مدیریت، اجزای یک پازل هستند که تصویر امنیت و آرامش را میسازند. تیم متخصص NetHelper آماده است تا این پازل را برای شما تکمیل کند.